과목 4. 데이터 모델링
제3장 논리 데이터 모델링
1. 이력 관리란 ?
데이터는 현재의 프로세스만 처리하고 버리는 것이 아니라 마치 후손에게 물려주어야 할 귀중한 문화유산처럼 오랜 기간의 데이터를 유지시켜 좀 더 가치있는 정보를 제공할 수 있는 밑거름이 되도록 해야 한다.
모든 업무는 언제 시작해서 언제 끝났는지에 관한 정보가 기록되어 있다. 가장 흔한 예로 주민등록 증의 뒷면을 보면 주소 변경란이 있다. 이사를 가서 주소지를 옮길 때마다 거기에는 주소 이력 정보 가 기입된다. 언제 어느 동으로 이사를 갔으며, 변경된 주소는 무엇이냐 하는 것 등이다.
예를 들면 통화 데이터에서 관리되고 있던 환율 데이터에 대한 다음과 같은 업무 요구 사항이 발생하면 환율에 대한 이력을 관리하게 된다.
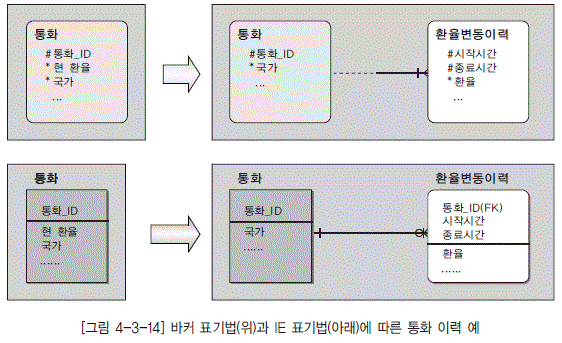
- 어제의 환율은 얼마인가?
- 오늘 아침의 환율은 얼마인가?
- 환율의 변화에 대한 추이 분석을 하고자 한다.

데이터 모델이 구현되어 실제 데이터가 들어가 있는 모습이다. 즉, 환율별로 이력이 관리되고 있는 모습을 보여주고 있다.
2. 이력 관리 대상 선정
가. 사용자 조사
데이터의 이력을 관리한다는 것은 관리하지 않을 때와 비교했을 때 많은 비용이 들어가는 일이다. 즉, 이력을 관리할 필요가 없는 데이터에 대해서 이력을 관리하는 것은 여러 가지 측면에서 낭비이다. 그래서 다음과 같은 질문에 대한 사용자의 검증 과정을 거쳐야 한다.
- 변경 내역을 감시할 필요가 있는가?
- 시간의 경과에 따라 데이터가 변할 수 있는가?
- 시간의 경과에 따라 관계가 변할 수 있는가?
- 과거의 데이터를 조회할 필요가 있는가?
- 과거 버전을 보관할 필요가 있는가?
나. 인력 데이터의 종류
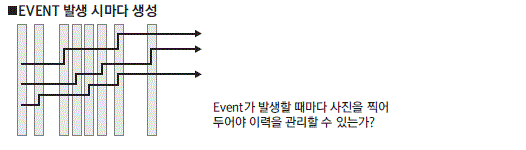
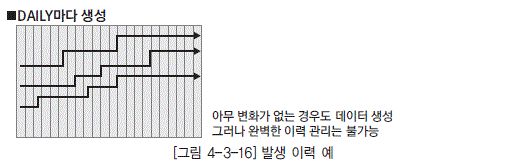
1) 발생 이력(OCCURRENCE HISTORY) 데이터
어떤 데이터가 발생할 때마다 이력 정보를 남겨야만 한다면 이력은 발생 이력이라고 볼 수 있다.
예를 들어 고객의 접속 기록을 남겨야만 하는 경우 고객이 웹사이트를 접속할 때마다 그 접속 데이터 를 남긴다면 이것을 발생 이력이라고 할 수 있다. 이 방법은 전통적으로 이력을 관리하는 방법으로 사용되어 왔다.
2) 변경 이력 (MODIFICATION HISTORY) 데이터
데이터가 변경될 때마다 변경 전과 후의 차이를 확인해야 한다면 변경 이력을 남길 수 있다. 예를 들어, 고객이 주문을 하고서 주문 정보를 변경하였을 때 이전 주문과 변경된 새로운 주문 정보를 관 리하기 위해서 변경된 새로운 주문 정보를 이력 정보로 남겨야 한다.
3) 진행 이력 (PROGRESS HISTORY) 데이터
업무의 진행에 따라 이 데이터를 이력 정보로 남겨야만 하는 경우가 있다. 가장 대표적인 것이 바로 주문과 같은 업무 처리이다. 물론 이력이 관리되는 형태는 위의 변경 이력과 같은 형태로 관리 된다. 예를 들면, 주문의 업무 처리는 구매 신청 -> 입금 완료-> 배송 준비 중 -> 배송 중 -> 배송 완료 혹은 주문 취소 등과 같은 업무 진행 상황이 있다. 대부분의 주문 업무 처리의 경우 각 단계가 언제 누구에 의해서 처리되고, 현재 단계는 무엇인지에 관한 정보가 필요한 경우가 많다. 이러한 경우의 업무를 처리하기 위해서는 진행 이력이 중요하다.
다. 이력 관리 형태
- 시점 이력 : 데이터의 변경이 발생한 시각만을 관리
- 선분 이력 : 데이터 변경의 시작 시점부터 그 상태의 종료 시점까지 관리
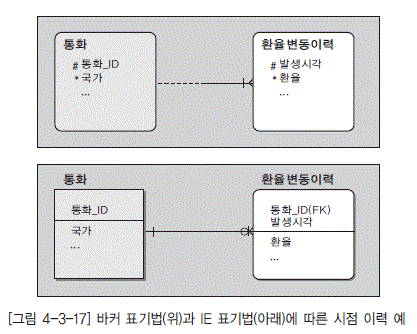
1) 시점 이력
특정 통화의 환율이 변경되면 새로운 인스턴스가 생겨나고(New Record), 그 시점의 해당 통화의 환율과 발생 시각을 기록/보관함으로써 환율이 어느 시점에 얼마의 값으로 변경되었다라는 정보를 관리하는 것이다.
2) 선분 이력
각 통화의 특정 기간 동안 유효한 환율을 관리
선분 이력 관리 유형
- 인스턴스 레벨 이력 관리 : 하나의 인스턴스의 어떤 변경이라도 발생하면 전체 인스턴스를 새롭게 생성하는 방식의 이력 관리 유형이다.
- 속성 레벨 이력 관리 : 이력을 관리할 대상 속성에서 변화가 생길 때만 이력을 생성하는 방식이다.
- 주제 레벨 이력 관리 : 내용이 유사하거나 연동될 확률이 높은 것별로 인스턴스 레벨 이력을 관리하는 방법이다.
3. 선분 이력 관리용 식별자 확정
가. 선분 이력에서 식별자 결정 시 고려사항
선분 이력을 관리하는 엔터티의 UID를 확정하는 것은 향후에 테이블로 만들어지고 사용될 때의 성능 측면도 고려되어야 한다.
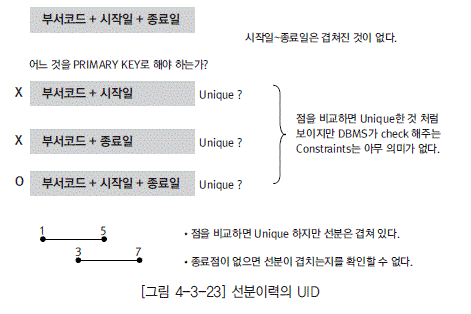
부서별로 이력이 관리되는 엔터티를 예를 들어 설명하면 의미적인 UID는 부서코드 + 이력시작일 + 이력종료일을 기본키로 하는 것이 유리하다.
하지만 이것은 [그림 4-3-23]에서과 같이 물리적인 측면, 즉 실제 데이터는 Unique하지만 의미적으로는 Unique하지 않는 일이 발생한다. 이러한 부분의 의미적인 Unique을 검증할 수 있는 조치를 병행해야 한다.
나. 선분 이력에서 종료점 처리 시 주의사항
1) 종료점이 미정이므로 NULL
- 논리적으로는 타당하지만 비교가 불가능
- 인덱스를 사용하지 못하므로 수행 속도 저하
2) 수렴하므로 최대치 부여
- 아직 종료되지 않았으므로 무한히 계속되는 것으로 간주
- 최대치 부여 (예; 일자라면 9999/12/31)
- 가능한 TABLE creation 시 Default constraints 부여
- 수행 속도에 유리
'자격증 > DASP' 카테고리의 다른 글
| [DAsP] 4-4-1절 물리 데이터 모델링 이해 (0) | 2022.06.02 |
|---|---|
| [DASP] 4-3장 논리 데이터 모델링 요약★ (0) | 2022.06.02 |
| [DAsP] 4-3-3절 엔터티 상세화 (0) | 2022.06.02 |
| [DAsP] 4-3-2절 속성 정의 (0) | 2022.06.01 |
| [DAsP] 4-3-1절 논리 데이터 모델링 이해 (0) | 2022.05.31 |